一些关键字的解释说明
.split(“\s”)
\\s表示空格、回车、换行等空白符\\s+表示一个或多个空格、回车、换行等空白符
.split(“\w+”)
表示匹配数字和字母下划线的多个字符
tuple元组
tuple是flink中自定义的一种组合类型,类似java中Map<String,String>,只不过Map只有两个字段,相当于Tuple2。
flink中tuple最多支持25个字段,不支持空字段.
复合类型有:
- Flink Java Tuples(Flink Java API的一部分):最多25个字段,空字段不支持
- Scala Case classes(包括Scala tuples):最多25个字段,空字段不支持
- Row:具有任意数量字段的元组,并支持空字段
- POJO:遵循某种Bean模式的类
tuple使用
最简单的情况是在元组的一个或多个字段上对元组进行分组:
DataStream<Tuple3<Integer,String,Long>> input = // [...]
KeyedStream<Tuple3<Integer,String,Long>,Tuple> keyed = input.keyBy(0)
元组在第一个字段(整数类型)上分组。
DataStream<Tuple3<Integer,String,Long>> input = // [...]
KeyedStream<Tuple3<Integer,String,Long>,Tuple> keyed = input.keyBy(0,1)
在这里,我们将元组分组在由第一个和第二个字段组成的复合键上。
关于嵌套元组的注释:如果你有一个带有嵌套元组的DataStream,例如:
DataStream<Tuple3<Tuple2<Integer, Float>,String,Long>> ds;
指定keyBy(0)将导致系统使用full Tuple2作为键(以Integer和Float为键)。
更多参考官网
map和flatMap
map
把数组流中的每一个值,使用所提供的函数执行一遍,一一对应。得到元素个数相同的数组流。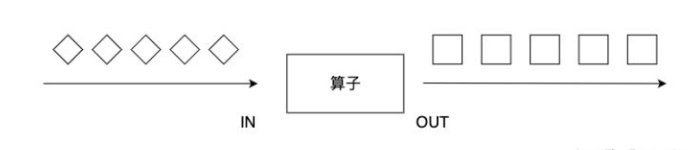
map算子对一个DataStream中的每个元素使用用户自定义的map函数进行处理,每个输入元素对应一个输出元素,最终整个数据流被转换成一个新的DataStream。输出的数据流DataStream[OUT]类型可能和输入的数据流DataStream[IN]不同。
flatMap
flat是扁平的意思。它把数组流中的每一个值,使用所提供的函数执行一遍,一一对应。得到元素相同的数组流。只不过,里面的元素也是一个子数组流。把这些子数组合并成一个数组以后,元素个数大概率会和原数组流的个数不同。
filter
filter算子对每个元素进行过滤,过滤的过程使用一个filter函数进行逻辑判断。对于输入的每个元素,如果filter函数返回True,则保留,如果返回False,则丢弃。
keyBy
绝大多数情况,我们要根据事件的某种属性或数据的某个字段进行分组,对一个分组内的数据进行处理。如下图所示,keyBy算子根据元素的形状对数据进行分组,相同形状的元素被分到了一起,可被后续算子统一处理。比如,多支股票数据流处理时,可以根据股票代号进行分组,然后对同一股票代号的数据统计其价格变动。又如,电商用户行为日志把所有用户的行为都记录了下来,如果要分析某一个用户行为,需要先按用户ID进行分组。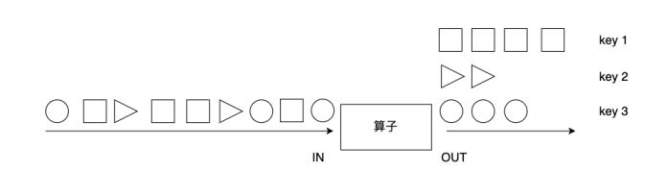
aggregation
常见的聚合操作有sum、max、min等,这些聚合操作统称为aggregation。aggregation需要一个参数来指定按照哪个字段进行聚合。跟keyBy相似,我们可以使用数字位置来指定对哪个字段进行聚合,也可以使用字段名。
与批处理不同,这些聚合函数是对流数据进行数据,流数据是依次进入Flink的,聚合操作是对之前流入的数据进行统计聚合。
- max算子对该字段求最大值,并将结果保存在该字段上。对于其他字段,该操作并不能保证其数值。
- maxBy算子对该字段求最大值,maxBy与max的区别在于,maxBy同时保留其他字段的数值,即maxBy可以得到数据流中最大的元素。
- 同样,min和minBy的区别在于,min算子对某字段求最小值,minBy返回具有最小值的元素。
其实,这些aggregation操作里已经封装了状态数据,比如,sum算子内部记录了当前的和,max算子内部记录了当前的最大值。由于内部封装了状态数据,而且状态数据并不会被清理,因此一定要避免在一个无限数据流上使用aggregation。
注意,对于一个KeyedStream,一次只能使用一个aggregation操作,无法链式使用多个。
reduce
前面几个aggregation是几个较为特殊的操作,对分组数据进行处理更为通用的方法是使用reduce算子。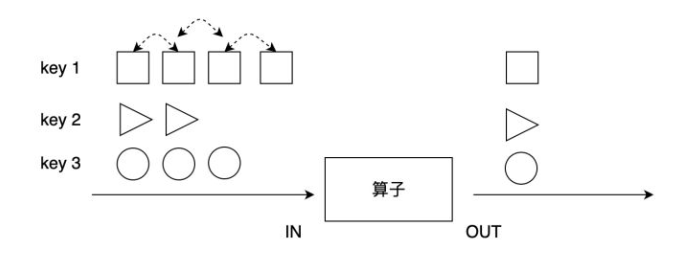
上图展示了reduce算子的原理:reduce在按照同一个Key分组的数据流上生效,它接受两个输入,生成一个输出,即两两合一地进行汇总操作,生成一个同类型的新元素。
DataStream<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(0)
//ReduceFunction定义了reduce方法,它主要是用来将两个同类型的值操作为一个同类型的值,第一个参数为前面reduce的结果,第二参数为当前的元素
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) {
System.out.println("value1:"+value1.f1+";value2:"+value2.f1);
return new Tuple2<>(value1.f0, value1.f1 + value2.f1);
}
});