介绍
首先我们先来了解下 Prometheus-Operator的架构图: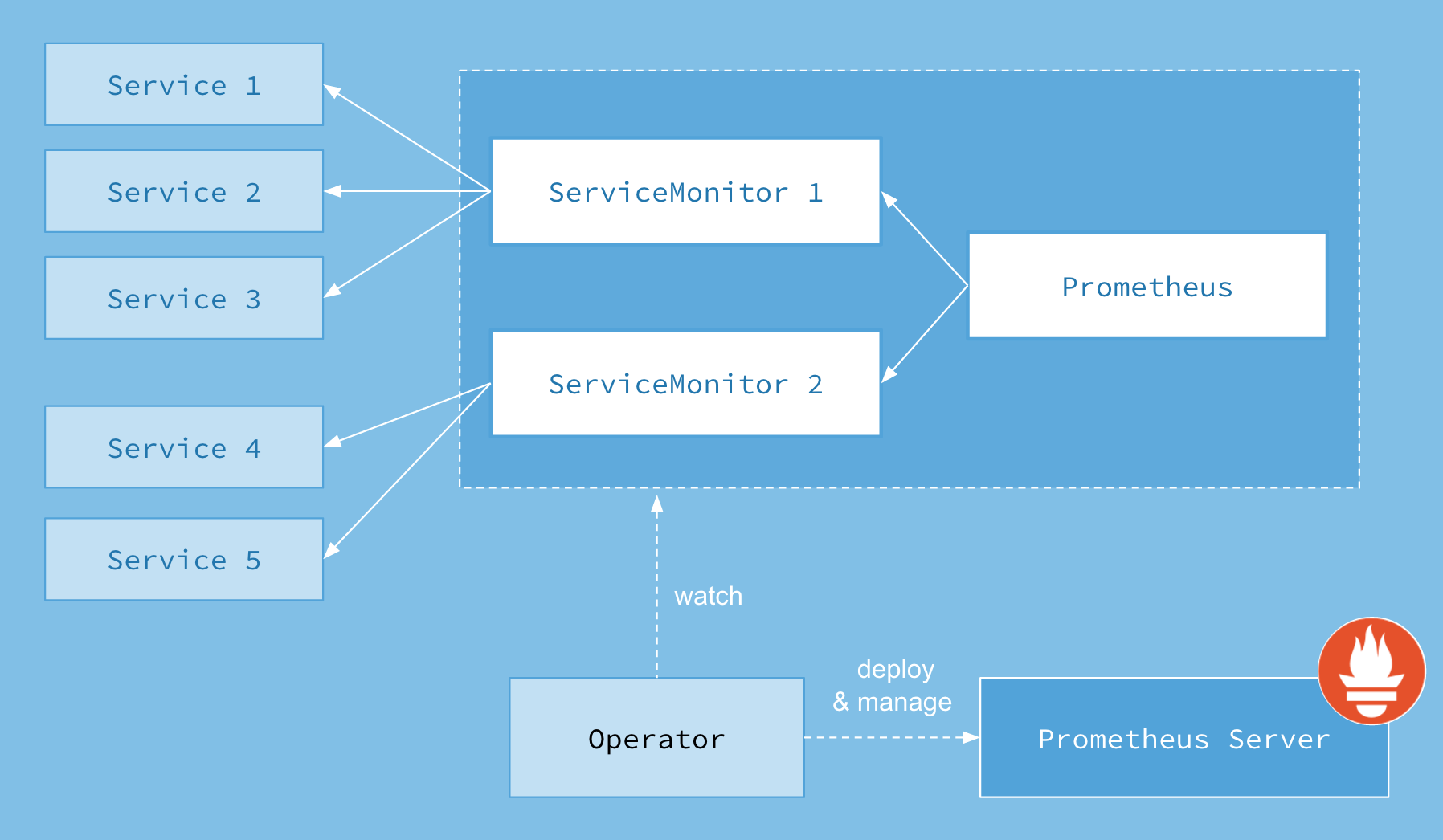
上图是Prometheus-Operator官方提供的架构图,其中Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的prometheus这种资源对象就是作为Prometheus Server存在,而ServiceMonitor就是exporter的各种抽象,exporter前面我们已经学习了,是用来提供专门提供metrics数据接口的工具,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的,当然alertmanager这种资源对象就是对应的AlertManager的抽象,而PrometheusRule是用来被Prometheus实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
查看stable/prometheus-operator的默认值
helm inspect values stable/prometheus-operator
将默认配置导出,备用
helm inspect values stable/prometheus-operator > prometheus-operator.yaml
提前将配置中涉及到的镜像下载好
#!/bin/sh
docker pull hub.deri.org.cn/k8s_monitor/alertmanager:v0.19.0
docker tag hub.deri.org.cn/k8s_monitor/alertmanager:v0.19.0 quay.io/prometheus/alertmanager:v0.19.0
docker rmi hub.deri.org.cn/k8s_monitor/alertmanager:v0.19.0
docker pull hub.deri.org.cn/k8s_monitor/ghostunnel:v1.4.1
docker tag hub.deri.org.cn/k8s_monitor/ghostunnel:v1.4.1 squareup/ghostunnel:v1.4.1
docker rmi hub.deri.org.cn/k8s_monitor/ghostunnel:v1.4.1
docker pull hub.deri.org.cn/k8s_monitor/kube-webhook-certgen:v1.0.0
docker tag hub.deri.org.cn/k8s_monitor/kube-webhook-certgen:v1.0.0 jettech/kube-webhook-certgen:v1.0.0
docker rmi hub.deri.org.cn/k8s_monitor/kube-webhook-certgen:v1.0.0
docker pull hub.deri.org.cn/k8s_monitor/prometheus-operator:v0.34.0
docker tag hub.deri.org.cn/k8s_monitor/prometheus-operator:v0.34.0 quay.io/coreos/prometheus-operator:v0.34.0
docker rmi hub.deri.org.cn/k8s_monitor/prometheus-operator:v0.34.0
docker pull hub.deri.org.cn/k8s_monitor/configmap-reload:v0.0.1
docker tag hub.deri.org.cn/k8s_monitor/configmap-reload:v0.0.1 quay.io/coreos/configmap-reload:v0.0.1
docker rmi pull hub.deri.org.cn/k8s_monitor/configmap-reload:v0.0.1
docker pull hub.deri.org.cn/k8s_monitor/prometheus-config-reloader:v0.34.0
docker tag hub.deri.org.cn/k8s_monitor/prometheus-config-reloader:v0.34.0 quay.io/coreos/prometheus-config-reloader:v0.34.0
docker rmi hub.deri.org.cn/k8s_monitor/prometheus-config-reloader:v0.34.0
docker pull hub.deri.org.cn/k8s_monitor/hyperkube:v1.12.1
docker tag hub.deri.org.cn/k8s_monitor/hyperkube:v1.12.1 k8s.gcr.io/hyperkube:v1.12.1
docker rmi hub.deri.org.cn/k8s_monitor/hyperkube:v1.12.1
docker pull hub.deri.org.cn/k8s_monitor/prometheus:v2.13.1
docker tag hub.deri.org.cn/k8s_monitor/prometheus:v2.13.1 quay.io/prometheus/prometheus:v2.13.1
docker rmi hub.deri.org.cn/k8s_monitor/prometheus:v2.13.1
docker pull hub.deri.org.cn/k8s_monitor/kube-state-metrics:v1.8.0
docker tag hub.deri.org.cn/k8s_monitor/kube-state-metrics:v1.8.0 quay.io/coreos/kube-state-metrics:v1.8.0
docker rmi hub.deri.org.cn/k8s_monitor/kube-state-metrics:v1.8.0
docker pull hub.deri.org.cn/k8s_monitor/node-exporter:v0.18.1
docker tag hub.deri.org.cn/k8s_monitor/node-exporter:v0.18.1 quay.io/prometheus/node-exporter:v0.18.1
docker rmi hub.deri.org.cn/k8s_monitor/node-exporter:v0.18.1
docker pull hub.deri.org.cn/k8s_monitor/k8s-sidecar:0.1.20
docker tag hub.deri.org.cn/k8s_monitor/k8s-sidecar:0.1.20 kiwigrid/k8s-sidecar:0.1.20
docker rmi hub.deri.org.cn/k8s_monitor/k8s-sidecar:0.1.20
docker pull hub.deri.org.cn/k8s_monitor/grafana:6.4.2
docker tag hub.deri.org.cn/k8s_monitor/grafana:6.4.2 grafana/grafana:6.4.2
docker rmi hub.deri.org.cn/k8s_monitor/grafana:6.4.2
用默认配置安装,指定了name、namespace等信息
helm install stable/prometheus-operator --name prometheus-operator --namespace monitoring -f prometheus-operator.yaml --set grafana.adminPassword=admin
查看pod运行情况
kubectl get pod -n monitoring
修改Grafana的service类型为NodePort,便于访问测试
kubectl edit svc prometheus-operator-grafana -n monitoring
通过下面命令,查看绑定宿主机的端口 ,访问测试密码安装时指定了admin/admin
kubectl get svc -n monitoring
卸载
helm delete prometheus-operator
helm delete --purge prometheus-operator
Prometheus-Operator安装时会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,卸载时一并删掉
kubectl delete crd prometheuses.monitoring.coreos.com
kubectl delete crd prometheusrules.monitoring.coreos.com
kubectl delete crd servicemonitors.monitoring.coreos.com
kubectl delete crd podmonitors.monitoring.coreos.com
kubectl delete crd alertmanagers.monitoring.coreos.com
修改prometheus-operator.yaml,配置ingress
# 例如AlterManager配置,默认情况enabled: false修改成true,hosts: []填入alterManager的域名
alertmanager:
ingress:
enabled: true
hosts: ["alert.deri.com"]
修改prometheus-operator.yaml,配置数据持久化
# 例如AlterManager,默认如下,是被注释掉的,取消注释,并填入你的storageClassName
storage: {}
# volumeClaimTemplate:
# spec:
# storageClassName: gluster
# accessModes: ["ReadWriteOnce"]
# resources:
# requests:
# storage: 50Gi
# selector: {}
alertmanager:
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-client
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
selector: {}
其它配置可以在默认配置prometheus-operator.yaml中查看并修改。
问题
问题一:
【摘自https://github.com/helm/charts/tree/master/stable/prometheus-operator】
KubeProxy【改完重启kubelet、docker服务】
The metrics bind address of kube-proxy is default to 127.0.0.1:10249 that prometheus instances cannot access to. You should expose metrics by changing metricsBindAddress field value to 0.0.0.0:10249 if you want to collect them.
Depending on the cluster, the relevant part config.conf will be in ConfigMap kube-system/kube-proxy or kube-system/kube-proxy-config. For example:
kubectl -n kube-system edit cm kube-proxy
apiVersion: v1
data:
config.conf: |-
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
# ...
# metricsBindAddress: 127.0.0.1:10249
metricsBindAddress: 0.0.0.0:10249
# ...
kubeconfig.conf: |-
# ...
kind: ConfigMap
metadata:
labels:
app: kube-proxy
name: kube-proxy
namespace: kube-system
问题二:
在不同环境安装时发现结果不一样,所有配置都一样,可能原因:
由于上述是通过helm安装的,首先通过命令helm repo list检查源是否一致;
通过helm search | grep prometheus查看 CHART VERSION APP VERSION 是否一致;
如果不一致通过helm repo update更新一下就可以了。