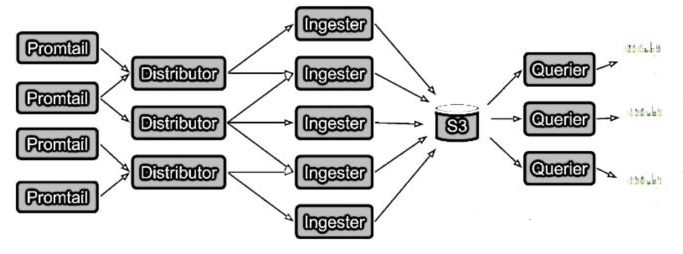
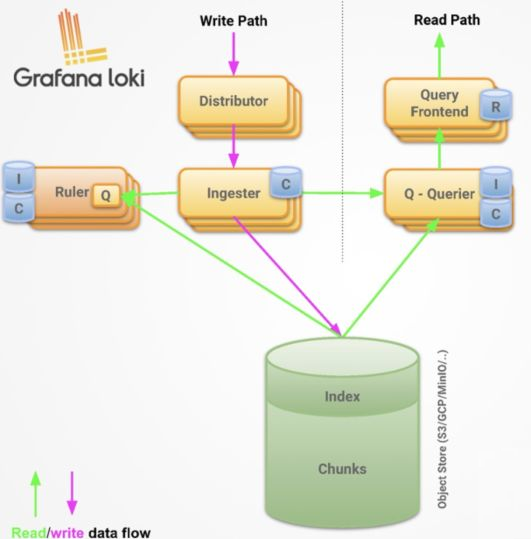
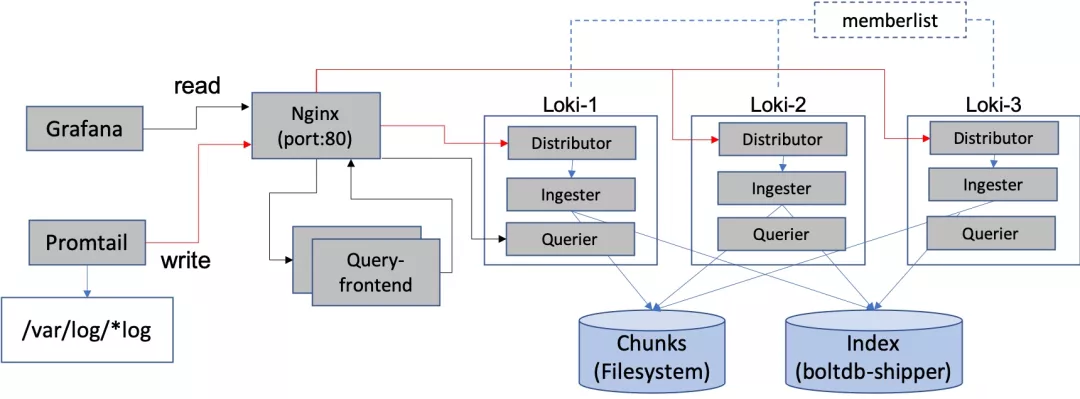
前提
步骤
docker run -d --name node-exporter -p 9100:9100 prom/node-exporter
启动完成可以访问http://IP:9100/metrics.
apiVersion: v1
kind: Endpoints
metadata:
name: node-data
namespace: kubesphere-monitoring-system
labels:
app.kubernetes.io/name: node-data
subsets:
- addresses:
- ip: 192.168.3.17
- ip: 192.168.3.19
- ip: 192.168.3.20
ports:
- port: 9100
name: http
apiVersion: v1
kind: Service
metadata:
name: node-data
namespace: kubesphere-monitoring-system
labels:
app.kubernetes.io/name: node-data
spec:
ports:
- port: 9100
name: http
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: node-exporter-data
namespace: kubesphere-monitoring-system
spec:
endpoints:
- port: http
namespaceSelector:
matchNames:
- kubesphere-monitoring-system
selector:
matchLabels:
app.kubernetes.io/name: node-data
创建完成可以prometheus web页面查看是否有新建的targets.
PromQL
- 计算CPU使用率
(1-(sum(increase(node_cpu_seconds_total{mode="idle"}[1m]))by(instance))/(sum(increase(node_cpu_seconds_total[1m]))by(instance)))*100
- 内存使用率
(1-(node_memory_MemAvailable_bytes{}/(node_memory_MemTotal_bytes{})))*100
- 磁盘分区
100 - (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs"} * 100)