| 命令 | 使用方法 | 说明 |
|---|---|---|
ls |
hadoop fs -ls |
返回文件详细信息或者目录列表 |
lsr |
hadoop fs -lsr |
递归返回文件详细信息或者目录列表,类似ls -R |
cat |
hadoop fs -cat URI |
返回文件内容 |
chgrp |
hadoop fs -chgrp [-R] GROUP URI |
改变文件所属组 |
chmod |
hadoop fs -chmod [-R] |
改变文件的权限 |
chown |
hadoop fs -chown [-R] |
改变文件拥有者 |
put |
hadoop fs -put |
上传文件 |
copyFromLocal |
hadoop fs -copyFromLocal URI |
上传文件 |
moveFromLocal |
hadoop fs -moveFromLocal |
上传文件 |
get |
hadoop fs -get [-ignorecrc] [-crc] |
下载文件 |
copyToLocal |
hadoop fs -copyToLocal [-ignorecrc] [-crc] |
下载文件 |
cp |
hadoop fs -cp URI |
复制文件 |
du |
hadoop fs -du URI |
显示所有文件大小 |
dus |
hadoop fs -dus |
显示文件大小 |
expunge |
hadoop fs -expunge |
清空回收站 |
getmerge |
hadoop fs -getmerge [addnl] |
|
mkdir |
hadoop fs -mkdir |
创建目录 |
mv |
hadoop fs -mv URI |
移动 |
rm |
hadoop fs -rm URI |
删除非空目录和文件 |
rmr |
hadoop fs -rmr |
递归删除 |
setrep |
hadoop fs -setrep [-R] |
改变文件副本数 |
stat |
hadoop fs -stat URI |
返回统计信息 |
tail |
hadoop fs -tail [-f] URI |
返回文件尾部1K字节内容 |
test |
hadoop fs -test -[ezd] URI |
-e检查文件是否存在,-z检查文件是否为空,-d检查文件是否是目录 |
text |
hadoop fs -text |
将文件输出和为文本格式,允许的格式zip TextRecordInputStream |
touchz |
hadoop fs -touchz |
创建一个空文件 |
springboot返回的时间时区不对
问题
import java.sql.Timestamp;
//对象中属性为
private Timestamp startTime;
private Timestamp endTime;
通过spring boot restful接口返回到前端,时区自动转换不对,晚八个小时:
{
"id": 0,
"startTime": "2020-04-29T06:15:00.000+0000",
"endTime": "2020-04-29T06:15:00.000+0000",
"taskResult": false
}
解决办法
application.yml中指定日期格式和时区
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: Asia/Shanghai
再次测试:
{
"id": 0,
"startTime": "2020-04-29 14:15:00",
"endTime": "2020-04-29 14:15:00",
"taskResult": false
}
Dataway集成springboot在线开发restful接口
创建一个spring boot web基本项目
引入dataway相关依赖
<!-- hasor-spring 负责 Spring 和 Hasor 框架之间的整合。 -->
<dependency>
<groupId>net.hasor</groupId>
<artifactId>hasor-spring</artifactId>
<version>4.1.3</version>
</dependency>
<!-- hasor-dataway 是工作在 Hasor 之上,利用 hasor-spring 我们就可以使用 dataway了。 -->
<dependency>
<groupId>net.hasor</groupId>
<artifactId>hasor-dataway</artifactId>
<version>4.1.3-fix20200414</version><!-- 4.1.3 包存在UI资源缺失问题 -->
</dependency>
<!-- 数据库相关依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.30</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
mysql数据库中创建表
CREATE TABLE `interface_info` (
`api_id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`api_method` varchar(12) NOT NULL COMMENT 'HttpMethod:GET、PUT、POST',
`api_path` varchar(512) NOT NULL COMMENT '拦截路径',
`api_status` int(2) NOT NULL COMMENT '状态:0草稿,1发布,2有变更,3禁用',
`api_comment` varchar(255) NULL COMMENT '注释',
`api_type` varchar(24) NOT NULL COMMENT '脚本类型:SQL、DataQL',
`api_script` mediumtext NOT NULL COMMENT '查询脚本:xxxxxxx',
`api_schema` mediumtext NULL COMMENT '接口的请求/响应数据结构',
`api_sample` mediumtext NULL COMMENT '请求/响应/请求头样本数据',
`api_create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`api_gmt_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`api_id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COMMENT='Dataway 中的API';
CREATE TABLE `interface_release` (
`pub_id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Publish ID',
`pub_api_id` int(11) NOT NULL COMMENT '所属API ID',
`pub_method` varchar(12) NOT NULL COMMENT 'HttpMethod:GET、PUT、POST',
`pub_path` varchar(512) NOT NULL COMMENT '拦截路径',
`pub_status` int(2) NOT NULL COMMENT '状态:0有效,1无效(可能被下线)',
`pub_type` varchar(24) NOT NULL COMMENT '脚本类型:SQL、DataQL',
`pub_script` mediumtext NOT NULL COMMENT '查询脚本:xxxxxxx',
`pub_script_ori` mediumtext NOT NULL COMMENT '原始查询脚本,仅当类型为SQL时不同',
`pub_schema` mediumtext NULL COMMENT '接口的请求/响应数据结构',
`pub_sample` mediumtext NULL COMMENT '请求/响应/请求头样本数据',
`pub_release_time`datetime DEFAULT CURRENT_TIMESTAMP COMMENT '发布时间(下线不更新)',
PRIMARY KEY (`pub_id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COMMENT='Dataway API 发布历史。';
create index idx_interface_release on interface_release (pub_api_id);
在application.properties中配置hasor-dataway和数据源
# 是否启用 Dataway 功能(必选:默认false)
HASOR_DATAQL_DATAWAY=true
# 是否开启 Dataway 后台管理界面(必选:默认false)
HASOR_DATAQL_DATAWAY_ADMIN=true
# dataway API工作路径(可选,默认:/api/)
HASOR_DATAQL_DATAWAY_API_URL=/api/
# dataway-ui 的工作路径(可选,默认:/interface-ui/)
HASOR_DATAQL_DATAWAY_UI_URL=/ui/
# SQL执行器方言设置(可选,建议设置)
HASOR_DATAQL_FX_PAGE_DIALECT=mysql
# db
spring.datasource.url=jdbc:mysql://192.168.41.128:3306/compare?useUnicode=true&characterEncoding=utf8&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.type:com.alibaba.druid.pool.DruidDataSource
# druid
spring.datasource.druid.initial-size=3
spring.datasource.druid.min-idle=3
spring.datasource.druid.max-active=10
spring.datasource.druid.max-wait=60000
spring.datasource.druid.stat-view-servlet.login-username=admin
spring.datasource.druid.stat-view-servlet.login-password=admin
spring.datasource.druid.filter.stat.log-slow-sql=true
spring.datasource.druid.filter.stat.slow-sql-millis=1
把数据源设置到 Hasor 容器中
首先新建一个 Hasor 的 模块,并且将其交给 Spring 管理。然后把数据源通过 Spring 注入进来。
@DimModule
@Component
public class ExampleModule implements SpringModule {
@Autowired
private DataSource dataSource = null;
@Override
public void loadModule(ApiBinder apiBinder) throws Throwable {
// .DataSource form Spring boot into Hasor
apiBinder.installModule(new JdbcModule(Level.Full, this.dataSource));
}
}
Hasor 启动的时候会调用 loadModule 方法,在这里再把 DataSource 设置到 Hasor 中。
在SprintBoot 中启用 Hasor
@EnableHasor()
@EnableHasorWeb()
@SpringBootApplication(scanBasePackages = { "com.deri.dataway.component" })
public class DatawayApplication {
public static void main(String[] args) {
SpringApplication.run(DatawayApplication.class, args);
}
}
启动应用
相关日志
_ _ ____ _
| | | | | _ \ | |
| |__| | __ _ ___ ___ _ __ | |_) | ___ ___ | |_
| __ |/ _` / __|/ _ \| '__| | _ < / _ \ / _ \| __|
| | | | (_| \__ \ (_) | | | |_) | (_) | (_) | |_
|_| |_|\__,_|___/\___/|_| |____/ \___/ \___/ \__|
2020-04-29 09:29:11.899 INFO 43336 --- [ main] net.hasor.dataway.config.DatawayModule : dataway api workAt /api/
2020-04-29 09:29:11.899 INFO 43336 --- [ main] n.h.c.environment.AbstractEnvironment : var -> HASOR_DATAQL_DATAWAY_API_URL = /api/.
2020-04-29 09:29:11.903 INFO 43336 --- [ main] net.hasor.dataway.config.DatawayModule : dataway admin workAt /ui/
访问接口管理页面进行在线接口开发
http://localhost:8080/ui/注意:地址最后的
/不能不写.
DataQL
新建一个restful接口,其中var query = @@sql()<% ... %>是用来定义SQL外部代码块,并将这个定义存入 query变量名中。<% %> 中间的就是SQL语句。
var query = @@sql()<%
select * from interface_info
%>
return query()
运行测试没有问题,就可以保存-发布了.
方便测试,请求方式可以写
GET,/api/后面写上接口的路径.如/api/test
发布成功后,就可以访问刚刚发布的接口了http://localhost:8080/api/test.
结果示例:
{
"success": true,
"message": "OK",
"code": 0,
"lifeCycleTime": 3,
"executionTime": 2,
"value": {
"id": 10,
"task_id": "m-20200904-3",
"task_type": 2,
"task_data_type": 3,
"start_time": 1586491785000,
"end_time": 1586491785000,
"task_result": 0,
"remark": "存在不一样"
}
}
参考链接
分布式存储
rowkey字典排序
排序规则
rowkey从高位到低位依照ASCII码表排序;如A排在a前面,a排在aaab前面;- 如果
rowkey一样,按照column family:qualifier排序; - 如果
column family:qualifier一样,按照时间戳排序;
充分利用rowkey会排序特性
- 如果热点数据的
rowkey前缀一样,则很容易被存储在同一RegionServer上,这样就会造成访问的性能瓶颈; rowkey前缀提供一个随机字符串,可以更好的分布在集群中,但是失去了排序特性;rowkey应该设计的精简,过长会加长硬盘和网络IO的开销.
rowkey排序
scan返回的数据是按照rowkey排序;API可以设置StartRow、StopRow查询范围内数据;
如rowkey是时间日期格式,以下可以查询2020年的数据:
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("20200101"));
scan.setStopRow(Bytes.toBytes("20210101"));
注意[
StartRow,StopRow)左闭右开.
ASCII编码
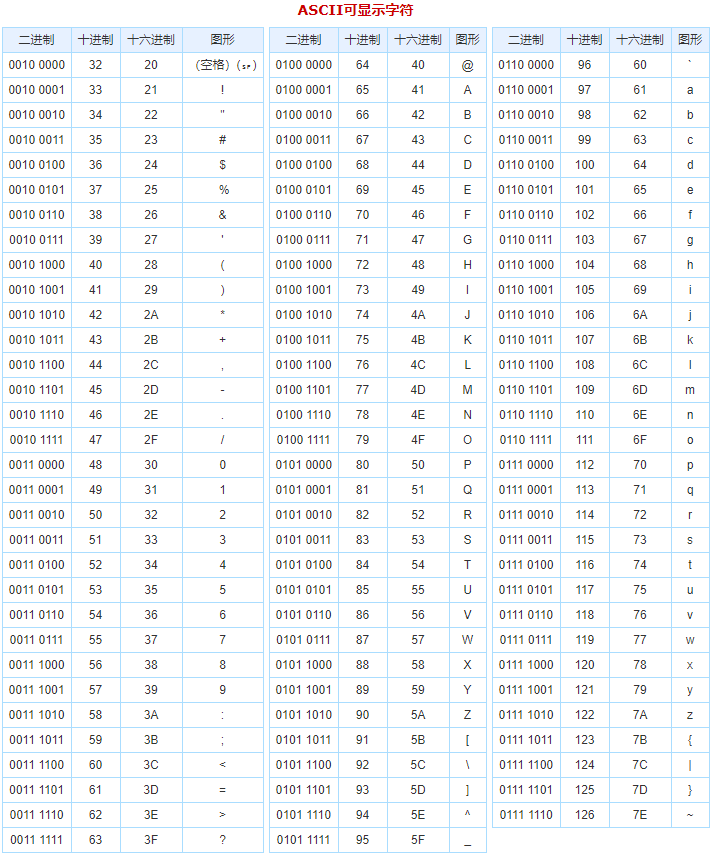
hbase-client java API 操作
spring boot集成hbase-client
参考上文使用
spring-boot-starter-hbase和RowMapper.
@Autowired
private HbaseTemplate hbaseTemplate;
创建表
/**
* 创建表
* @return
* @throws IOException
*/
public String createTable() throws IOException {
Admin admin = hbaseTemplate.getConnection().getAdmin();
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(table_name));
hTableDescriptor.addFamily(new HColumnDescriptor(column_family));
if (admin.tableExists(TableName.valueOf(table_name))) {
return "tableExists";
} else {
admin.createTable(hTableDescriptor);
return "ok";
}
}
批量插入数据
/**
* 批量插入数据
* @param i
*/
public void puts(int i) {
List<Mutation> puts = new ArrayList<>();
// 设值
while (i > 0) {
Put put = new Put(Bytes.toBytes(Long.toString(18752038428L - i)));
put.addColumn(Bytes.toBytes(column_family), Bytes.toBytes("name"), Bytes.toBytes("JThink" + i));
put.addColumn(Bytes.toBytes(column_family), Bytes.toBytes("age"), Bytes.toBytes(i));
puts.add(put);
i--;
}
this.hbaseTemplate.saveOrUpdates(table_name, puts);
}
根据rowkey查询数据
/**
* 根据rowkey查询数据
* @param row
* @return
*/
public PeopleDto get(String row) {
PeopleDto dto = this.hbaseTemplate.get(table_name, row, new PeopleRowMapper());
return dto;
}
根据rowkey删除数据
/**
* 根据rowkey删除数据
*/
public void delete(String rk) {
Mutation delete = new Delete(Bytes.toBytes(rk));
this.hbaseTemplate.saveOrUpdate(table_name, delete);
}
批量查询数据
/**
* 区间查找 [startRow, stopRow)
* @param startRow
* @param stopRow
* @return
*/
public List<PeopleDto> query(String startRow, String stopRow) {
Scan scan = new Scan(Bytes.toBytes(startRow), Bytes.toBytes(stopRow));
scan.setCaching(5000);
List<PeopleDto> dtos = this.hbaseTemplate.find(table_name, scan, new PeopleRowMapper());
return dtos;
}
注意查找的结果遵循
左闭右开原则.
过滤
// 要查询的表
HTable table = new HTable(conf, "table1");
// 要查询的字段
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("a"));
scan.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("b"));
// where条件
// a = 1
SingleColumnValueFilter a = new SingleColumnValueFilter(Bytes.toBytes("cf"),
Bytes.toBytes("a"), CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(1)));
filterList.addFilter(filter);
// b = 2
SingleColumnValueFilter b = new SingleColumnValueFilter(Bytes.toBytes("cf"),
Bytes.toBytes("b"), CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(2)));
// and
FilterList filterList = new FilterList(Operator.MUST_PASS_ALL, a, b);
scan.setFilter(filterList);