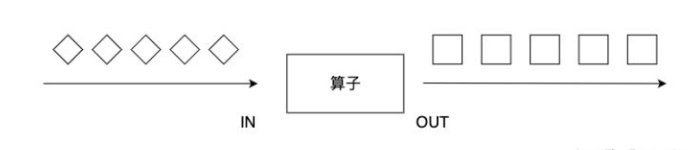
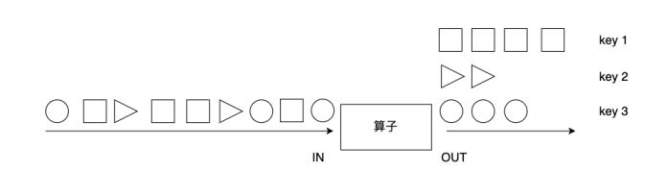
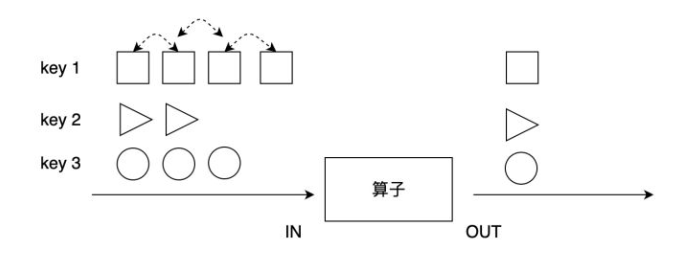
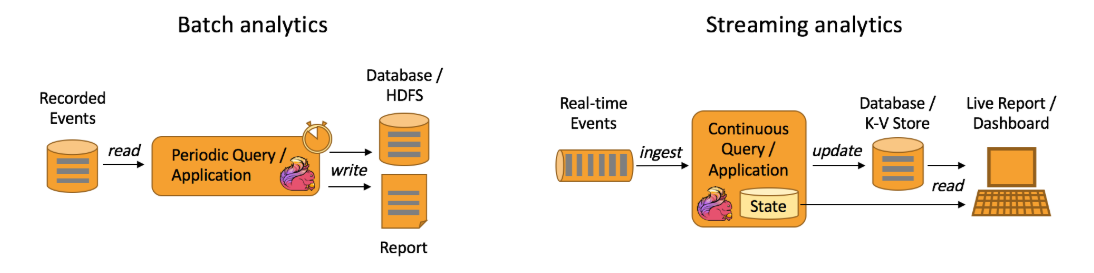
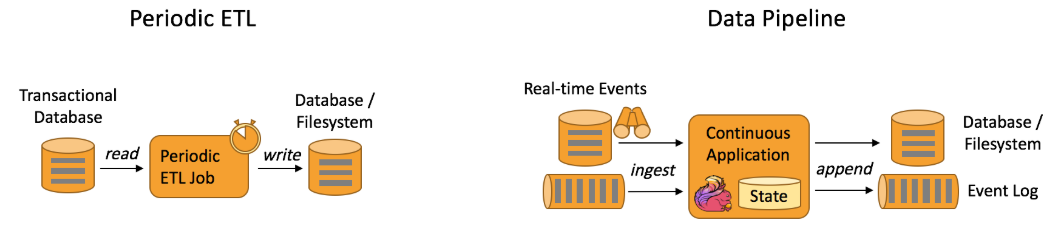
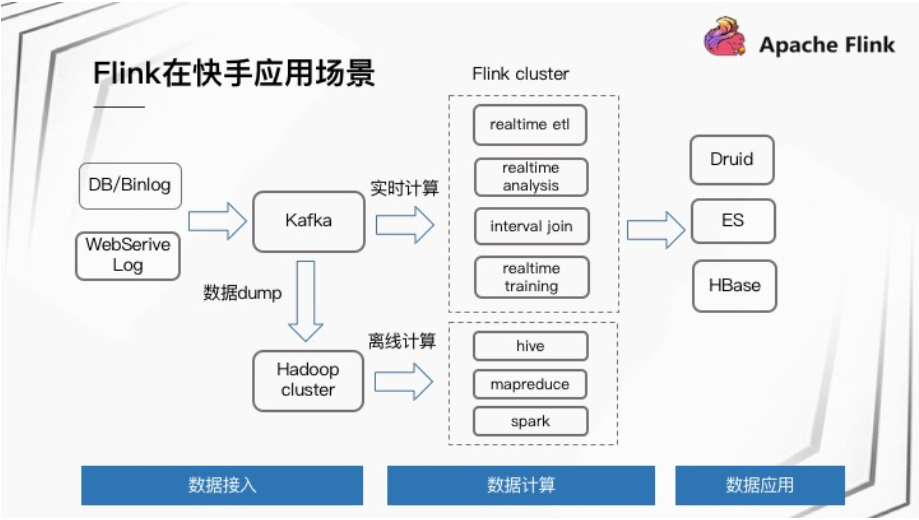
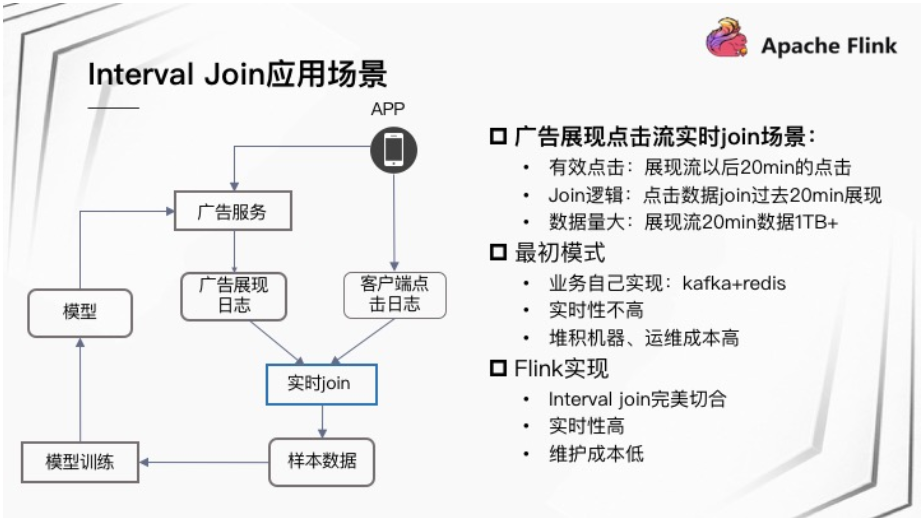
::用法
jdk8中使用了::的用法。就是把方法当做参数传到stream内部,使stream的每个元素都传入到该方法里面执行一下,双冒号运算就是Java中的[方法引用],[方法引用]的格式是:
类名::方法名
例如:
表达式:
person -> person.getAge();
使用双冒号:
Person :: getAge
stream和parallelStream
用于生成数据流
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
//生成顺序流
strings.stream()
//生成并行流
strings.parallelStream()
forEach
用于迭代数据流中每个数据
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
strings.stream().forEach(System.out::println);
map
对数据流中每个数据执行方法
List<Integer> strings = Arrays.asList(1,2,3,4,5,6,7,8);
// 每个数据加1操作
strings.stream().map(x -> x + 1).forEach(System.out::println);
distinct
去重
List<Integer> strings = Arrays.asList(1,2,3,4,4,5,5,5,6,7,8);
// 去除重复的4,5,5
strings.stream().distinct().forEach(System.out::println);
filter
过滤
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
// 获取空字符串的数量
long count = strings.stream().filter(string -> string.isEmpty()).count();
//获取非空数量
long count = strings.stream().filter(string -> !string.isEmpty()).count();
limit
限制流的大小
List<Integer> strings = Arrays.asList(1,2,3,4,4,5,5,5,6,7,8);
// 只会打印前4个
strings.stream().limit(4).forEach(System.out::println);
sorted
排序
List<Integer> strings = Arrays.asList(11,12,13,14,4,15,5,5,6,7,8);
// 排序打印
strings.stream().sorted().forEach(System.out::println);
Collectors
归约操作
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());
System.out.println("筛选列表: " + filtered);
String mergedString = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.joining(", "));
System.out.println("合并字符串: " + mergedString);
summaryStatistics
统计
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
IntSummaryStatistics stats = numbers.stream().mapToInt((x) -> x).summaryStatistics();
System.out.println("列表中最大的数 : " + stats.getMax());
System.out.println("列表中最小的数 : " + stats.getMin());
System.out.println("所有数之和 : " + stats.getSum());
System.out.println("平均数 : " + stats.getAverage());