Bookinfo示例简介
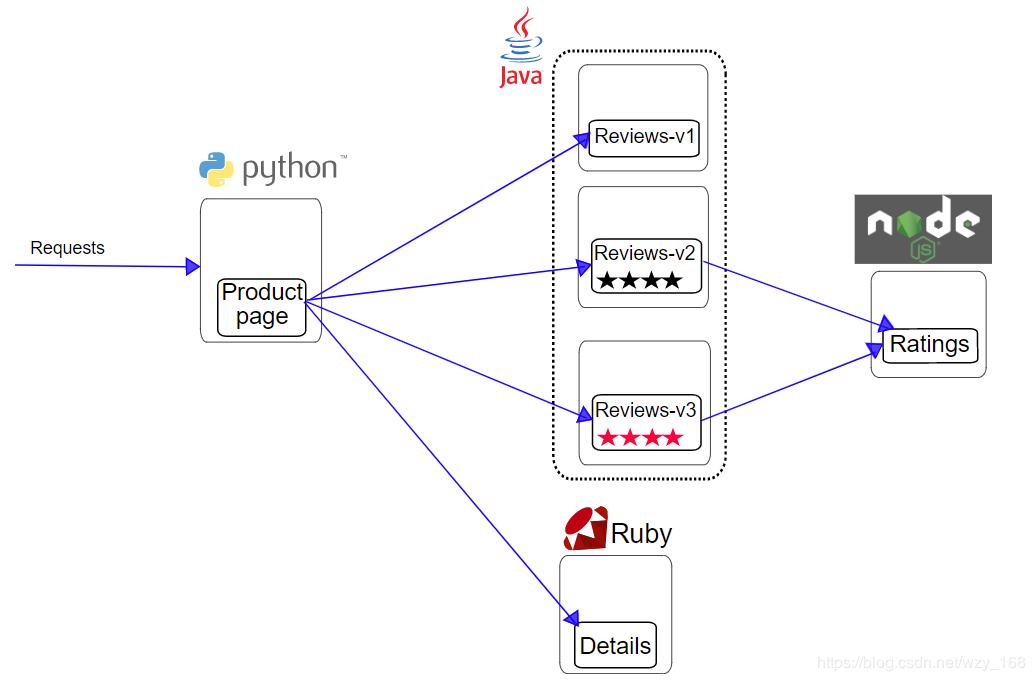
Bookinfo是istio官网示例,应用程序分为四个单独的微服务:
productpage。该productpage微服务调用details和reviews微服务来填充页面。details。该details微服务包含图书信息。reviews。该reviews微服务包含了书评。它们调用ratings微服务。ratings。该ratings微服务包含预定伴随书评排名信息。
reviews微服务有3个版本:
- 版本
v1不会调用该ratings服务。
- 版本
v2调用该ratings服务,并将每个等级显示为1到5个黑星★。
- 版本
v3调用该ratings服务,并将每个等级显示为1到5个红色星号★。
![Bookinfo架构图]()
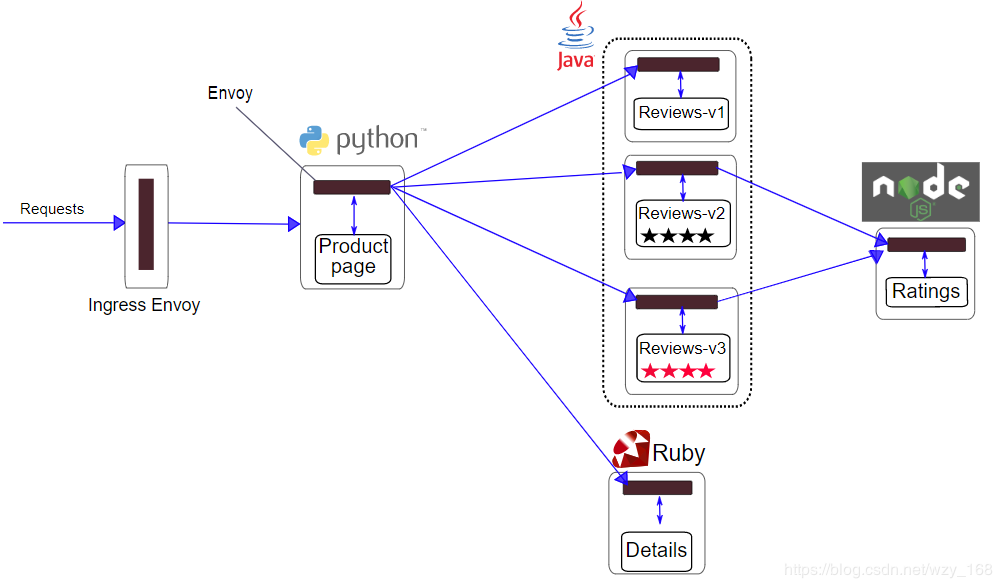
Bookinfo在Istio中架构
如果想要在Istio中运行Bookinfo,Bookinfo本身不需要任何改动,只需要为Bookinfo的微服务注入Istio的Sidecar。最终架构图如下:
![Bookinfo架构图]()
所有的微服务都与Envoy边车打包在一起,该Envoy边车拦截对服务的出/入请求,并与Istio控制面交互,提供路由、采集、实施各种策略等。
启动Bookinfo服务,参考官网
进入istio目录
[root@k8s-master istio-1.4.2]
/root/istio/istio-1.4.2
设置namespace自动注入sidecar
kubectl label namespace default istio-injection=enabled
部署bookinfo服务
kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
你也可以手动为这个yaml注入sidecar再部署,参考Istio使用【sidecar注入】
kubectl apply -f <(istioctl kube-inject -f samples/bookinfo/platform/kube/bookinfo.yaml)
确定启动完成
[root@k8s-master istio-1.4.2]
NAME READY STATUS RESTARTS AGE
details-v1-74f858558f-7gx6r 2/2 Running 0 31h
productpage-v1-8554d58bff-fwcj4 2/2 Running 0 31h
ratings-v1-7855f5bcb9-r7z5l 2/2 Running 0 31h
reviews-v1-59fd8b965b-jppqr 2/2 Running 0 31h
reviews-v2-d6cfdb7d6-rx648 2/2 Running 0 31h
reviews-v3-75699b5cfb-qpdjm 2/2 Running 0 31h
[root@k8s-master istio-1.4.2]
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
details ClusterIP 10.102.10.128 <none> 9080/TCP 31h
productpage ClusterIP 10.110.251.239 <none> 9080/TCP 31h
ratings ClusterIP 10.99.146.247 <none> 9080/TCP 31h
reviews ClusterIP 10.102.77.22 <none> 9080/TCP 31h
确定程序运行正常
kubectl exec -it $(kubectl get pod -l app=ratings -o jsonpath='{.items[0].metadata.name}') -c ratings -- curl productpage:9080/productpage | grep -o "<title>.*</title>"
<title>Simple Bookstore App</title>
定义应用的入口网关
kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
确认网关已创建
[root@k8s-master istio-1.4.2]
NAME AGE
bookinfo-gateway 30h
下面可以通过Isito的入口网关来访问了,在访问前,需要确定Isito网关IP和端口。
获取Istio入口网关IP和端口:参考官网
kubectl get svc istio-ingressgateway -n istio-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-ingressgateway LoadBalancer 10.110.94.234 <pending> 15020:32344/TCP,80:31380/TCP,443:31390/TCP,31400:31400/TCP,15029:31933/TCP,15030:30470/TCP,15031:31361/TCP,15032:31151/TCP,15443:31081/TCP 2d2h
如果EXTERNAL-IP设置了该值,则您的环境具有可用于入口网关的外部负载平衡器。如果EXTERNAL-IP值是<none>(或永久<pending>),则您的环境不为入口网关提供外部负载平衡器。在这种情况下,您可以使用服务的节点端口来访问网关。
确定端口
确定IP
可以通过下面命令找个hostIP
[root@k8s-master istio-1.4.2]
---
state:
running:
startedAt: "2019-12-24T06:46:29Z"
hostIP: 192.168.1.212
phase: Running
podIP: 10.244.3.136
qosClass: Burstable
---
也可以通过下面的命令找到Ingress部署的节点。
[root@k8s-master istio-1.4.2]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
istio-ingressgateway-6b7bfd7459-wljhh 1/1 Running 0 2d2h 10.244.3.136 k8s-02 <none> <none>
访问Bookinfo应用
浏览器访问刚刚或者的IP+端口+/productpage,例如我的是http://192.168.1.212:31380/productpage
![Reviewer-v1]()
![Reviewer-v2]()
![Reviewer-v3]()
不停的刷新页面,可以看到返回的Reviewer是不同的版本。
简单分析下
针对samples/bookinfo/networking/bookinfo-gateway.yaml,我们可以看看默认配置做了啥。
[root@k8s-master istio-1.4.2]
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: bookinfo-gateway
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- "*"
gateways:
- bookinfo-gateway
http:
- match:
- uri:
exact: /productpage
- uri:
prefix: /static
- uri:
exact: /login
- uri:
exact: /logout
- uri:
prefix: /api/v1/products
route:
- destination:
host: productpage
port:
number: 9080
首先创建一个Gateway,这是Istio的一个自定义资源类型(CRD),它创建了这个bookinfo应用的网关bookinfo-gateway,使用了istio默认的controller——ingressgateway,如上文,istio的ingress网关定义了很多类型端口,这里bookinfo-gateway使用了80端口,域名使用的通配符 * 。
定义VirtualService,这里需要绑定刚刚创建的bookinfo-gateway,定义了匹配的URI和后台服务。