介绍
Loki是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签。项目受 Prometheus 启发,官方的介绍就是:Like Prometheus, but for logs.,类似于 Prometheus 的日志系统。
与其他日志聚合系统相比,Loki具有下面的一些特性:
- 不对日志进行全文索引。通过存储压缩非结构化日志和仅索引元数据,Loki 操作起来会更简单,更省成本。
- 通过使用与 Prometheus 相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率更高。
- 特别适合储存 Kubernetes Pod 日志; 诸如 Pod 标签之类的元数据会被自动删除和编入索引。
- 受 Grafana 原生支持。
Loki 由以下3个部分组成: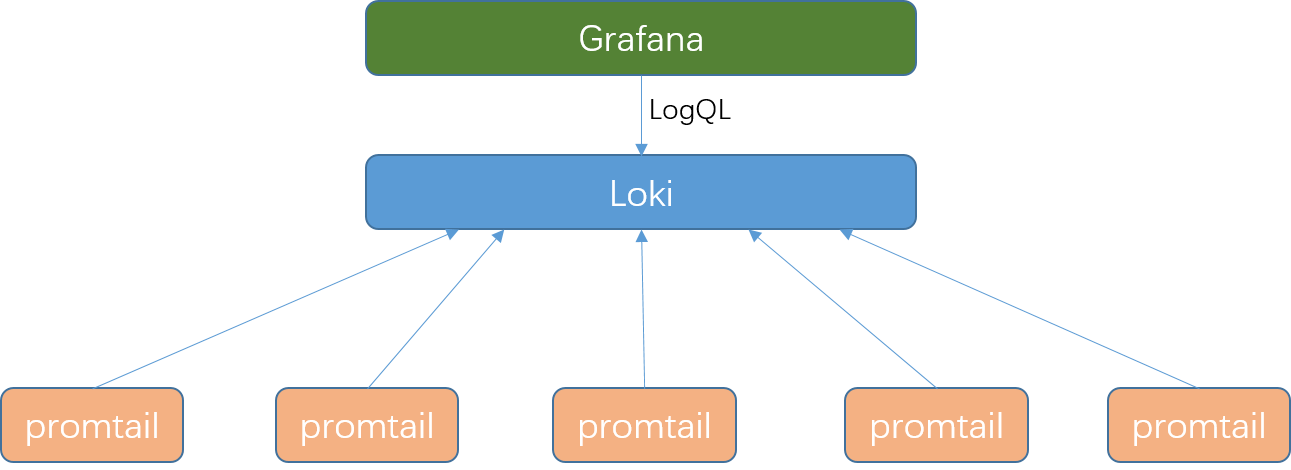
- loki是主服务器,负责存储日志和处理查询。
- promtail是代理,负责收集日志并将其发送给 loki 。
- Grafana用于 UI 展示。
Loki安装
参考官网
添加/更新helm
helm repo add loki https://grafana.github.io/loki/charts
helm repo update
安装loki(使用默认配置)
helm upgrade --install loki loki/loki-stack
安装loki(设置namespace)
helm upgrade --install loki --namespace=loki loki/loki
安装loki(更改一些配置)
helm upgrade --install loki loki/loki-stack --set grafana.enabled=true,prometheus.enabled=true,prometheus.alertmanager.persistentVolume.enabled=false,prometheus.server.persistentVolume.enabled=false
这边loki使用的镜像是
grafana/loki:v1.2.0,建议提前拉取下来。docker pull grafana/loki:v1.2.0其它一些信息,可以参考官网配置。
Promtail安装
参考官网
helm upgrade --install promtail loki/promtail --set "loki.serviceName=loki" --namespace=loki
这边loki使用的镜像是
grafana/promtail:v1.2.0,建议提前拉取下来。docker pull grafana/promtail:v1.2.0其它一些信息,可以参考官网配置。
集成Grafana,实现页面查询日志
前文使用Helm一键安装Prometheus Operator已经安装了grafana服务,我们可以直接使用。
登录grafana,选择添加数据源
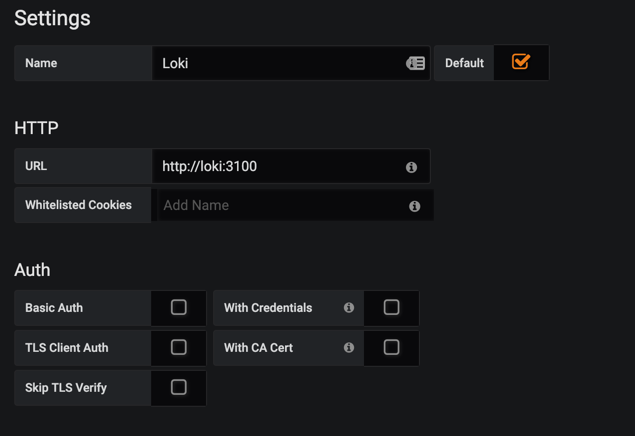
数据源列表中选择Loki,配置服务地址
如果
grafana与loki在同一个namespace,只需写服务名即可。
如果是在不同的namespace,那么要写完整DNS地址。
切换到grafana左侧区域的Explore,进入loki页面
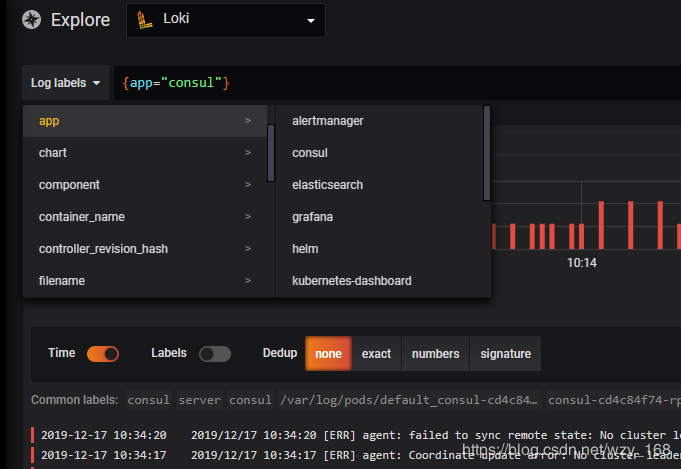
点击Log labels就可以把当前系统采集的日志标签给显示出来,可以根据这些标签进行日志的过滤查询
常见问题
...........
level=error ts=2019-12-17T05:43:00.189385282Z caller=filetarget.go:272 msg="failed to tail file, stat failed" error="stat /var/log/pods/kube-system_kube-flannel-ds-amd64-btn7m_5088625c-bba8-41d6-86c8-dc738d3b43ab/kube-flannel/3.log: no such file or directory" filename=/var/log/pods/kube-system_kube-flannel-ds-amd64-btn7m_5088625c-bba8-41d6-86c8-dc738d3b43ab/kube-flannel/3.log
level=error ts=2019-12-17T05:43:00.192476724Z caller=filetarget.go:272 msg="failed to tail file, stat failed" error="stat /var/log/pods/kube-system_kube-flannel-ds-amd64-btn7m_5088625c-bba8-41d6-86c8-dc738d3b43ab/install-cni/5.log: no such file or directory" filename=/var/log/pods/kube-system_kube-flannel-ds-amd64-btn7m_5088625c-bba8-41d6-86c8-dc738d3b43ab/install-cni/5.log
......
提示找不到/var/log/pods目录下的日志文件,无法tail。
首先我们可以进入promtail容器内,到该目录下查看下是否有该文件,通过cat命令看看是否有日志。
默认安装promtail,它会将主机/var/log/pods和/var/lib/docker/containers目录通过volumes方式挂载到promtail容器内。如果安装docker和k8s都是采用默认配置,应该不会存在读不到日志的问题。
{
"name": "docker",
"hostPath": {
"path": "/var/lib/docker/containers",
"type": ""
}
},
{
"name": "pods",
"hostPath": {
"path": "/var/log/pods",
"type": ""
}
}
本人因为主机系统盘太小,设置了docker镜像的目录到挂载磁盘/data目录下,所以需要修改默认volumes配置。
{
"name": "docker",
"hostPath": {
"path": "/data/docker/containers",
"type": ""
}
},
{
"name": "pods",
"hostPath": {
"path": "/var/log/pods",
"type": ""
}
}
//注意对应的volumeMounts也要修改
"volumeMounts": [
{
"name": "docker",
"readOnly": true,
"mountPath": "/data/docker/containers"
},
{
"name": "pods",
"readOnly": true,
"mountPath": "/var/log/pods"
}
]
上面volumes和volumeMounts都要修改,因为/var/log/pods目录下的日志文件其实是个软链接,指向的是docker/containers目录下的日志文件。如果只修改了volumes,那么promtail容器内可以找到日志文件,但是打开确实空的,因为它只是个软连接。
[root@node1 log]# ll /var/log/pods/monitoring_promtail-bs5cs_5bc5bc90-bac9-480d-b291-4caadeff2236/promtail/
total 4
lrwxrwxrwx 1 root root 162 Dec 17 14:04 0.log -> /data/docker/containers/db45d5118e9508817e1a2efa3c9da68cfe969a2b0a3ed42619ff61a29cc64e5f/db45d5118e9508817e1a2efa3c9da68cfe969a2b0a3ed42619ff61a29cc64e5f-json.log