ProcessFunction简介
ProcessFunction是flink中最底层的API。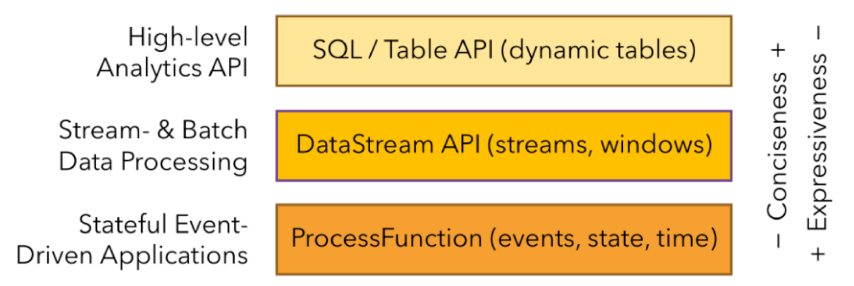
Flink的一些算子和函数能够进行一些时间上的操作,但是不能获取算子当前的Processing Time或者是Watermark时间戳,调用起来简单但功能相对受限。如果想获取数据流中Watermark的时间戳,或者在时间上前后穿梭,需要使用ProcessFunction系列函数,它们是Flink体系中最底层的API,提供了对数据流更细粒度的操作权限。Flink SQL是基于这些函数实现的,一些需要高度个性化的业务场景也需要使用这些函数。
目前,这个系列函数主要包括KeyedProcessFunction、ProcessFunction、CoProcessFunction、KeyedCoProcessFunction、ProcessJoinFunction和ProcessWindowFunction等多种函数,这些函数各有侧重,但核心功能比较相似,主要包括两点:
- 状态:我们可以在这些函数中访问和更新
Keyed State。 - 定时器(Timer):像定闹钟一样设置定时器,我们可以在时间维度上设计更复杂的业务逻辑。使用前先在Timer中注册一个未来的时间,当这个时间到达,闹钟会“响起”,程序会执行一个回调函数,回调函数中执行一定的业务逻辑。
ProcessFunction使用
ProcessFunction有两个重要的接口processElement和onTimer
其中processElement函数在源码中的Java签名如下:
// 处理数据流中的一条元素
public abstract void processElement(I value, Context ctx, Collector<O> out)
processElement方法处理数据流中的一条元素,并通过Collector<O>输出出来。Context是它的区别于FlatMapFunction等普通函数的特色,开发者可以通过Context来获取时间戳,访问TimerService,设置Timer。
另外一个接口是onTimer:
// 时间到达后的回调函数
public void onTimer(long timestamp, OnTimerContext ctx, Collector<O> out)
这是一个回调函数,当到了“闹钟”时间,Flink会调用onTimer,并执行一些业务逻辑。这里也有一个参数OnTimerContext,它实际上是继承了前面的Context,与Context几乎相同。
使用Timer的方法主要逻辑为:
- 在
processElement方法中通过Context注册一个未来的时间戳t。这个时间戳的语义可以是Processing Time,也可以是Event Time,根据业务需求来选择。 - 在
onTimer方法中实现一些逻辑,到达t时刻,onTimer方法被自动调用。
获取、注册和删除Timer
从
Context中,我们可以获取一个TimerService,这是一个访问时间戳和Timer的接口。我们可以通过
Context.timerService.registerProcessingTimeTimer或Context.timerService.registerEventTimeTimer这两个方法来注册Timer,只需要传入一个时间戳即可。我们可以通过
Context.timerService.deleteProcessingTimeTimer和Context.timerService.deleteEventTimeTimer来删除之前注册的Timer。此外,还可以从中获取当前的时间戳:
Context.timerService.currentProcessingTime和Context.timerService.currentWatermark。
注意,我们只能在KeyedStream上注册Timer。每个Key下可以使用不同的时间戳注册不同的Timer,但是每个Key的每个时间戳只能注册一个Timer。如果想在一个DataStream上应用Timer,可以将所有数据映射到一个伪造的Key上,但这样所有数据会流入一个算子子任务。
Flink 框架会自动忽略同一时间的重复注册Timer。
使用ProcessFunction实现Join
如果想从更细的粒度上实现两个数据流的Join,可以使用CoProcessFunction或KeyedCoProcessFunction。这两个函数都有processElement1和processElement2方法,分别对第一个数据流和第二个数据流的每个元素进行处理。两个数据流的数据类型以及输出类型可以互不相同。尽管数据来自两个不同的流,但是他们可以共享同样的状态,所以可以参考下面的逻辑来实现Join:
- 创建一到多个状态,两个数据流都能访问到这些状态,这里以状态
a为例。 processElement1方法处理第一个数据流,更新状态a。processElement2方法处理第二个数据流,根据状态a中的数据,生成相应的输出。