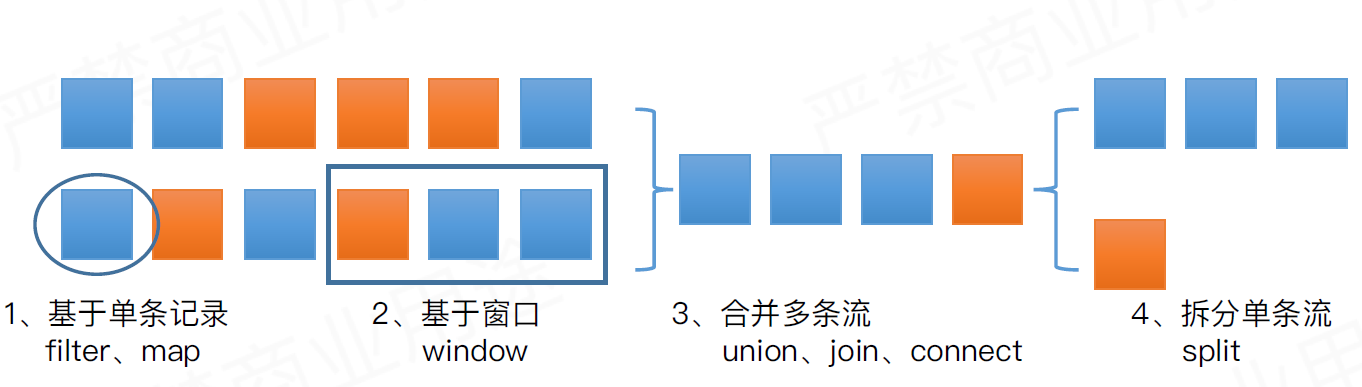
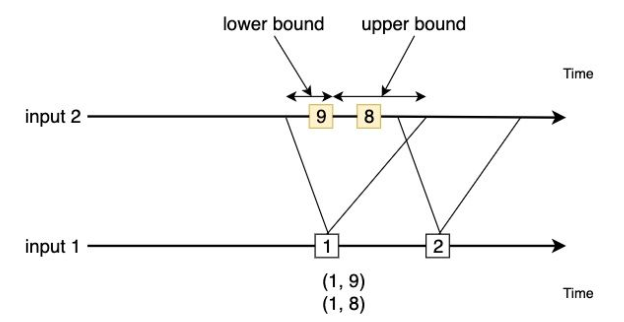
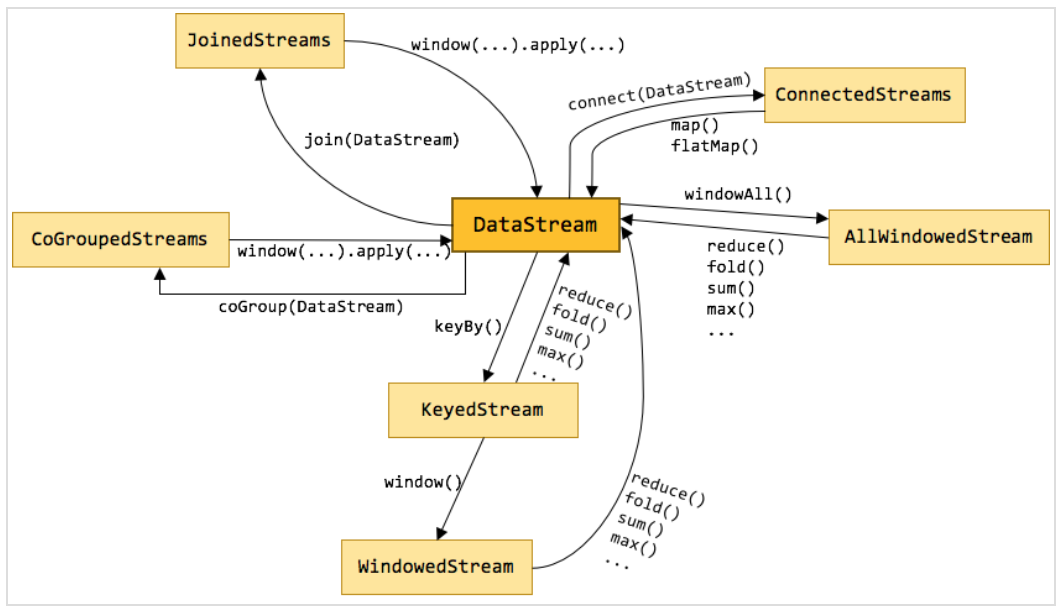
案例说明
本案例主要结合kafka,实现:
- 通过flink,向kafka中写入模拟数据book贩卖信息,包括书籍id、类型、价格、时间戳;
- flink任务每五秒输出最近五分钟,根据id,不同书籍卖出的总价。
代码
BookPojo.java
书籍book基本类
package com.deri.pojo.util;
/**
* @ClassName: BookPojo
* @Description: TODO
* @Author: wuzhiyong
* @Time: 2020/3/20 9:48
* @Version: v1.0
**/
public class BookPojo {
private int id;
private String type;
private int price;
private long timestamp;
public BookPojo() {
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
}
Books.java
创建模拟数据,6本书,随机返回一本书。
package com.deri.pojo.util;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* @ClassName: Books
* @Description: TODO
* @Author: wuzhiyong
* @Time: 2020/3/20 10:52
* @Version: v1.0
**/
public class Books {
public static BookPojo getBook(){
List<BookPojo> bookPojos = new ArrayList<>();
{
BookPojo book1 = new BookPojo();
book1.setId(1);
book1.setType("cs");
book1.setPrice(80);
bookPojos.add(book1);
}
{
BookPojo book1 = new BookPojo();
book1.setId(2);
book1.setType("math");
book1.setPrice(70);
bookPojos.add(book1);
}
{
BookPojo book1 = new BookPojo();
book1.setId(3);
book1.setType("ph");
book1.setPrice(60);
bookPojos.add(book1);
}
{
BookPojo book1 = new BookPojo();
book1.setId(4);
book1.setType("cs");
book1.setPrice(50);
bookPojos.add(book1);
}
{
BookPojo book1 = new BookPojo();
book1.setId(5);
book1.setType("math");
book1.setPrice(40);
bookPojos.add(book1);
}
{
BookPojo book1 = new BookPojo();
book1.setId(6);
book1.setType("ph");
book1.setPrice(30);
bookPojos.add(book1);
}
return bookPojos.get(new Random().nextInt(6));
}
}
MyPojoSource.java
flink数据源,随机返回一本书并设置当时时间戳当作流水,并随机暂停几秒钟。
package com.deri.pojo.util;
import com.alibaba.fastjson.JSON;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
/**
* @ClassName: MyNoParalleSource
* @Description: TODO
* @Author: wuzhiyong
* @Time: 2020/3/4 10:15
* @Version: v1.0
**/
//使用并行度为1的source
public class MyPojoSource implements SourceFunction<String> {//1
private boolean isRunning = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isRunning) {
BookPojo book = Books.getBook();
book.setTimestamp(System.currentTimeMillis());
ctx.collect(JSON.toJSONString(book));
Thread.sleep(new Random().nextInt(8000));
}
}
@Override
public void cancel() {
isRunning = false;
}
}
KafkaPojoProducer.java
flink将书籍贩卖流水转成json字符串,输入到kafka中。
package com.deri.pojo;
import com.deri.pojo.util.MyPojoSource;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
/**
* @ClassName: KafkaProducer
* @Description: TODO
* @Author: wuzhiyong
* @Time: 2020/3/4 10:16
* @Version: v1.0
**/
public class KafkaPojoProducer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> text = env.addSource(new MyPojoSource()).setParallelism(1)/*设置并行度*/;
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.41.128:9092");
//new FlinkKafkaProducer("topn",new KeyedSerializationSchemaWrapper(new SimpleStringSchema()),properties,FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>("pojosource", new SimpleStringSchema(), properties);
/*
//event-timestamp事件的发生时间
producer.setWriteTimestampToKafka(true);
*/
text.addSink(producer);
env.execute("POJO Kafka Source");
}
}
KafkaPojoStream.java
从上面pojosource主题中,获取书籍贩卖流水,每10秒打印出过去5分钟每种书贩卖的总价。
package com.deri.pojo;
import com.alibaba.fastjson.JSON;
import com.deri.pojo.util.BookPojo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.typeutils.TupleTypeInfo;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import java.util.Properties;
/**
* @ClassName: KafkaWordCount
* @Description: 从kafka主题中读取数据,进行word count
* @Author: wuzhiyong
* @Time: 2020/3/18 15:05
* @Version: v1.0
**/
public class KafkaPojoStream {
public static void main(String[] args) throws Exception {
// 创建Flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.41.128:9092");
properties.setProperty("group.id", "flink-group");
String inputTopic = "pojosource";
String outputTopic = "pojosink";
FlinkKafkaConsumer<String> consumer =
new FlinkKafkaConsumer<>(inputTopic, new SimpleStringSchema(), properties);
FlinkKafkaProducer<String> producer =
new FlinkKafkaProducer<>(outputTopic, new SimpleStringSchema(), properties);
//设置EventTime,结合assignTimestampsAndWatermarks一起使用
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<String> stream = env.addSource(consumer);
DataStream<String> bookPojoDataStream = stream.map(s -> JSON.parseObject(s, BookPojo.class))
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<BookPojo>() {
@Override
public long extractAscendingTimestamp(BookPojo bookPojo) {
return bookPojo.getTimestamp();
}
})
// .filter(bookPojo -> bookPojo.getType().equalsIgnoreCase("cs"))
.keyBy("id")
// .timeWindow(Time.seconds(10))
//设置一个5分钟滑动窗口,每10秒滑动一次
.timeWindow(Time.minutes(5), Time.seconds(10))
//这边使用更加通用的reduce处理,累加书籍贩卖总流水
.reduce(new ReduceFunction<BookPojo>() {
@Override
public BookPojo reduce(BookPojo bookPojo, BookPojo t1) throws Exception {
BookPojo book = new BookPojo();
book.setId(bookPojo.getId());
book.setPrice(bookPojo.getPrice()+ t1.getPrice());
book.setType(t1.getType());
book.setTimestamp(t1.getTimestamp());
return book;
}
})
.map(s -> JSON.toJSONString(s));
// bookPojoDataStream.addSink(producer);
bookPojoDataStream.print();
// execute
env.execute("kafka streaming pojo");
}
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
pom.xml
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.deri</groupId>
<artifactId>flink_kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>Flink Quickstart Job</name>
<url>http://www.myorganization.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.10.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.54</version>
</dependency>
<!-- Add connector dependencies here. They must be in the default scope (compile). -->
<!-- Example:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
-->
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.deri.kafka.KafkaProducer</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. -->
<plugin>
<groupId>org.eclipse.m2e</groupId>
<artifactId>lifecycle-mapping</artifactId>
<version>1.0.0</version>
<configuration>
<lifecycleMappingMetadata>
<pluginExecutions>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<versionRange>[3.1.1,)</versionRange>
<goals>
<goal>shade</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<versionRange>[3.1,)</versionRange>
<goals>
<goal>testCompile</goal>
<goal>compile</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
</pluginExecutions>
</lifecycleMappingMetadata>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>