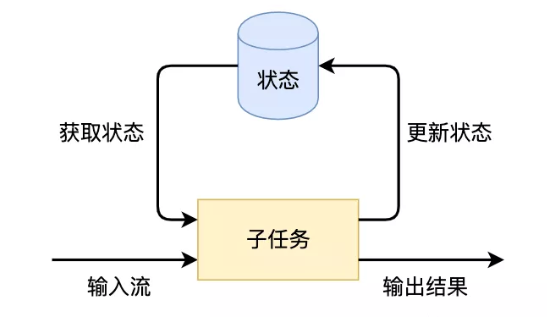
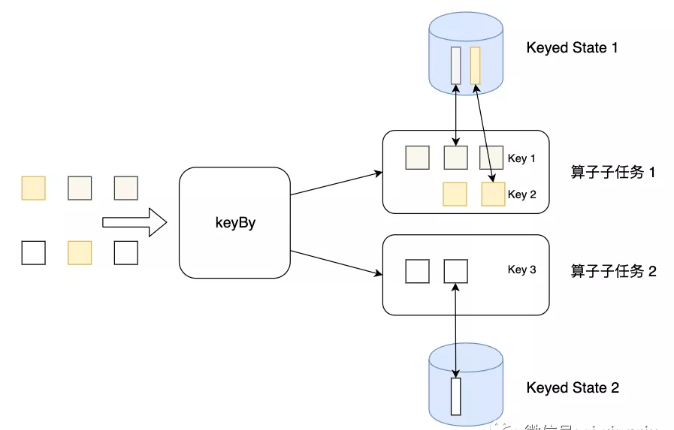
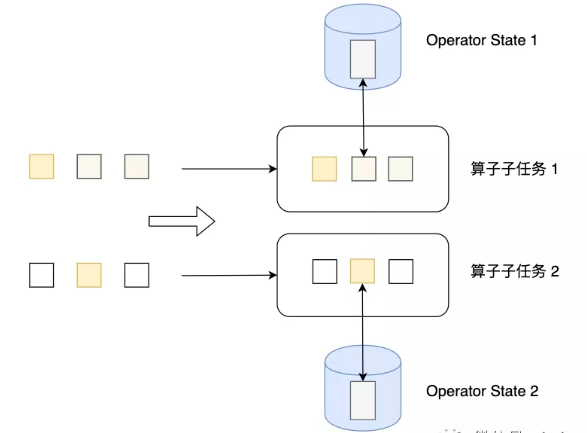
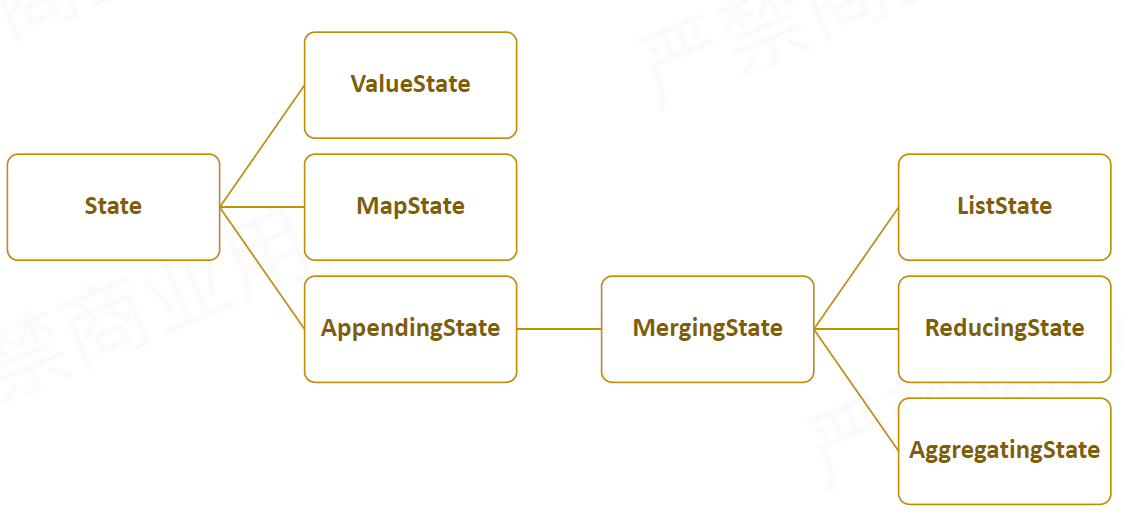
问题
{"id":5,"price":40,"ts":1585125854697,"type":"math"}
{"id":3,"price":60,"ts":1585125861687,"type":"ph"}
{"id":1,"price":80,"ts":1585125862380,"type":"cs"}
模拟数据如上所示,时间字段是13位时间戳格式,在flink sql中直接转成TIMESTAMP格式会有问题。
参考阿里云日期函数TO_TIMESTAMP,文档中示例支持三种入参,
TIMESTAMP TO_TIMESTAMP(BIGINT time)
TIMESTAMP TO_TIMESTAMP(VARCHAR date)
TIMESTAMP TO_TIMESTAMP(VARCHAR date, VARCHAR format)
实际使用flink 1.10版本测试,TO_TIMESTAMP不能直接将BIGINT转成TIMESTAMP.
[ERROR] Could not execute SQL statement. Reason:
org.apache.calcite.sql.validate.SqlValidatorException: Cannot apply 'TO_TIMESTAMP' to arguments of type 'TO_TIMESTAMP()'. Supported form(s): 'TO_TIMESTAMP()' 'TO_TIMESTAMP(, )'
创建UDF,并用SQL client测试
创建一个UDF,传入一个Long型时间戳,返回Timestamp格式
public class TimeUdf extends ScalarFunction {
private Long timestamp;
public TimeUdf(Long timestamp) {
this.timestamp = timestamp;
}
public Timestamp eval(Long timestamp){
return new Timestamp(timestamp);
}
}
UDF需要的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
使用maven打包成jar,并拷贝到flink目录lib中,重启flink。
mvn clean package
修改sql-client-defaults.yaml配置
...
- name: bookpojo
type: source-table
connector:
property-version: 1
type: kafka
version: "universal"
topic: pojo
startup-mode: earliest-offset
properties:
zookeeper.connect: localhost:2181
bootstrap.servers: localhost:9092
group.id: testGroup
format:
property-version: 1
type: json
schema: "ROW<id INT, type STRING, price INT, ts BIGINT>"
schema:
- name: id
data-type: INT
- name: type
data-type: STRING
- name: price
data-type: INT
- name: ts
data-type: BIGINT
functions:
- name: TimeUdf
from: class
class: com.deri.udx.TimeUdf
constructor:
- type: BIGINT
value: 111111111
启动SQL client
./bin/sql-client.sh embedded
SQL查询
select * from bookpojo;
select id,price,type,TimeUdf(ts) AS ts from bookpojo;
最新研究:LONG型时间戳可以直接转成TIMESTAMP格式
需要在ROW中定义为LONG,Schema中定义为TIMESTAMP
CREATE TABLE `t` (
ctm TIMESTAMP,
) WITH (
'format.schema' = 'ROW<ctm LONG>'
)
sql-client-defaults.yaml中详细配置,测试成功
tables:
- name: bookpojo
type: source-table
update-mode: append
connector:
property-version: 1
type: kafka
version: "universal"
topic: pojo
startup-mode: earliest-offset
properties:
zookeeper.connect: localhost:2181
bootstrap.servers: localhost:9092
group.id: testGroup
format:
property-version: 1
type: json
schema: "ROW<id INT, type STRING, price INT, ts LONG>"
schema:
- name: id
data-type: INT
- name: type
data-type: STRING
- name: price
data-type: INT
- name: tss
data-type: TIMESTAMP
rowtime:
timestamps:
type: "from-field"
from: "ts"
watermarks:
type: "periodic-bounded"
delay: "60000"